Architecture of Recurrent Neural Networks
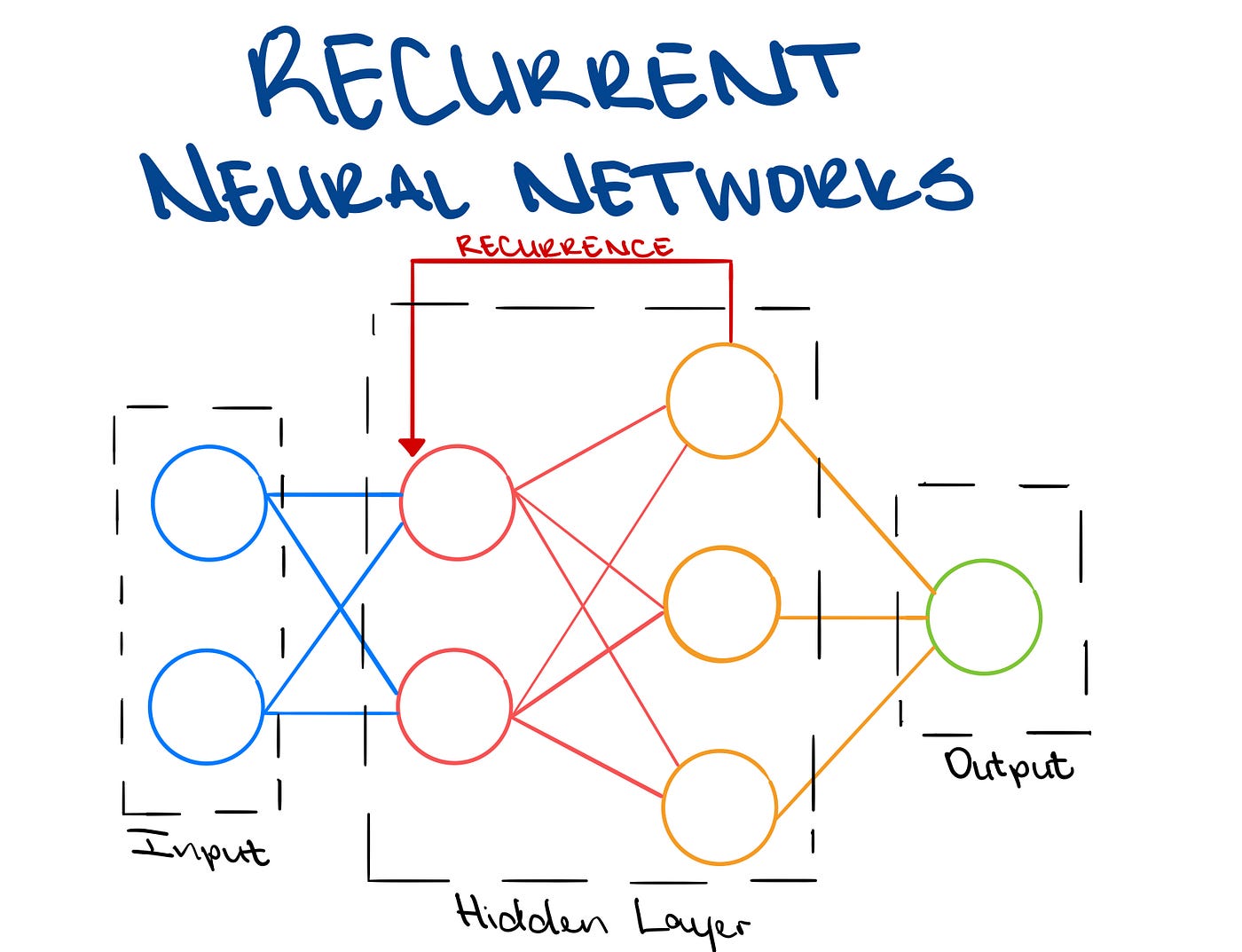
The architecture of a Recurrent Neural Network (RNN) consists of the following key components:
-
Input Layer:
- Represents the initial input to the network.
- For sequential data, each element of the sequence is presented to the network at different time steps.
-
Recurrent Connections:
- Connections between neurons that form directed cycles, allowing information to be passed from one time step to the next.
- These connections enable the network to maintain a memory of previous inputs and capture temporal dependencies.
-
Hidden Layers:
- Layers of neurons that process the input and produce outputs at each time step.
- The hidden layers enable the network to learn and represent complex patterns within sequential data.
-
Output Layer:
- Produces the final output of the network.
- The architecture of the output layer depends on the nature of the task, such as classification, regression, or sequence generation.
-
Activation Function:
- Typically, each neuron in the network applies an activation function to its input and produces an output.
- Common activation functions include sigmoid, hyperbolic tangent (tanh), or rectified linear unit (ReLU), depending on the specific requirements of the task.
The basic architecture described above represents a simple RNN. However, traditional RNNs often suffer from the vanishing gradient problem, making it difficult to capture long-term dependencies in the data. To address this issue, more advanced RNN architectures have been developed, including:
These advanced architectures enhance the capability of RNNs to learn and represent sequential patterns, making them more effective for tasks involving time series data, natural language processing, and other applications with sequential dependencies.
Thank you,