Decision Trees
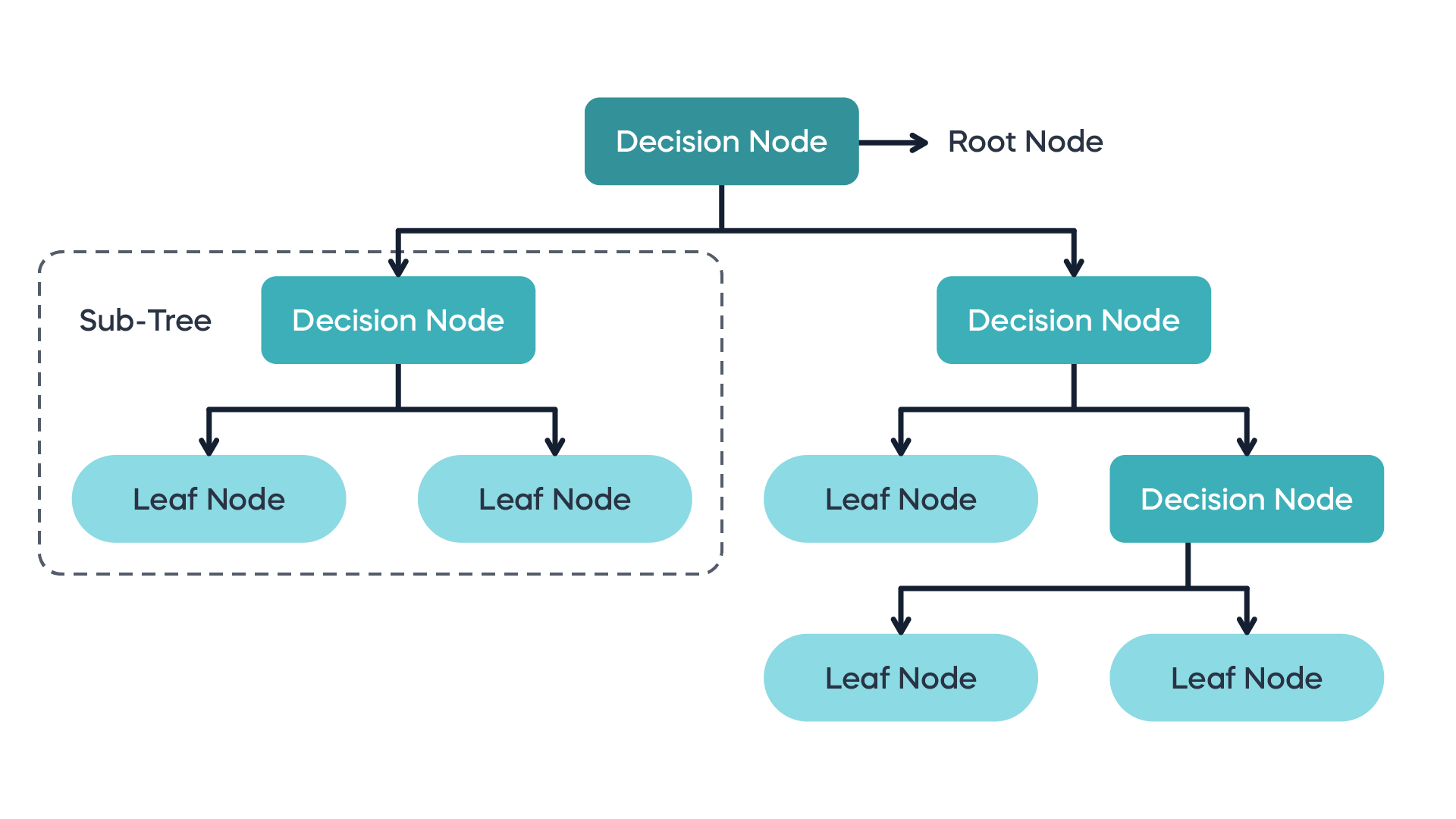
Decision trees are a popular machine learning algorithm with several advantages that make them suitable for various tasks and scenarios:
-
Interpretability:
- Decision trees produce a set of rules that are easy to understand and interpret. Each decision node represents a feature, and each leaf node represents a class label or a continuous value. This interpretability is valuable for explaining the reasoning behind the model's predictions, especially in domains where transparency and explainability are crucial, such as healthcare or finance.
-
No Data Preprocessing Required:
- Decision trees can handle both numerical and categorical data without the need for extensive preprocessing such as scaling, normalization, or encoding categorical variables. This makes them particularly convenient for datasets with mixed data types.
-
Non-Parametric:
- Decision trees are non-parametric models, meaning they do not make any assumptions about the underlying data distribution. They can capture complex relationships between features and the target variable without being restricted to specific functional forms. This flexibility makes decision trees suitable for capturing nonlinear relationships and interactions in the data.
-
Handles Missing Values:
- Decision trees can handle missing values in the dataset by using surrogate splits or assigning the most frequent class in the case of categorical variables. This robustness to missing data simplifies data preprocessing and imputation techniques.
-
Feature Importance:
- Decision trees provide a measure of feature importance, indicating which features are most influential in making predictions. This information can be valuable for feature selection, identifying relevant variables, and gaining insights into the underlying data patterns.
-
Robust to Outliers:
- Decision trees are robust to outliers in the data as they partition the feature space based on information gain or impurity measures. Outliers may affect individual splits but are less likely to impact the overall model performance.
-
Efficient for Large Datasets:
- With efficient tree-building algorithms such as CART (Classification and Regression Trees) or ID3 (Iterative Dichotomiser 3), decision trees can handle large datasets with relatively low computational overhead. Additionally, decision tree ensembles like Random Forests or Gradient Boosting Machines (GBMs) further improve performance while maintaining scalability.
-
Ensemble Methods:
- Decision trees can be combined into ensemble methods such as Random Forests or Gradient Boosting Machines, which aggregate multiple trees to improve predictive accuracy and generalization performance. Ensemble methods help mitigate overfitting and enhance model robustness.
-
Versatility:
- Decision trees can be applied to both classification and regression tasks, making them versatile across a wide range of applications, including healthcare, finance, marketing, and industrial domains.
Overall, the simplicity, interpretability, versatility, and robustness of decision trees make them a valuable tool in the machine learning toolkit, particularly in situations where transparency, ease of interpretation, and flexibility are paramount.
Thank you,